苹果正在与英伟达合作,想让 AI 的响应速度更快

近日,苹果与英伟达宣布合作,旨在加速和优化大语言模型(LLM)的推理性能。
为了改善传统自回归 LLM 推理效率低和内存带宽小的问题,今年早些时候,苹果机器学*的研究人员发布并开源了一种名为「」( ,循环草稿模型)的推测解码技术。
▲图源:
目前, 已经整合到英伟达的可扩展推理方案「LLM」当中,后者是基于「」深度学*编译框架的专为优化 LLM 推理而设计的开源库,支持包括「」等推测解码方法。
不过,由于 所包含的算法使用了之前从未用过的运算符,所以英伟达方面添加了新的运算符,或者公开了现有的运算符,大大提高了 LLM 适应复杂模型和解码方式的能力。

▲图源:
据悉, 推测解码通过三个关键技术来加速 LLM 的推理过程:
RNN 草稿模型
动态树注意力算法
知识蒸馏训练
RNN 草稿模型是 的「核心」组件。它使用循环神经网络( ),基于 LLM 的「隐藏状态」来预测接下来可能出现的 序列,其能够捕捉局部的时间依赖性,从而提高预测准确性。
这个模型的工作原理是:LLM 在文本生成过程中生成一个初始 token, RNN 草稿模型利用该 token 和 LLM 的最后一层隐藏状态作为输入进行束搜索(Beam ),进而生成多个候选 序列。
与传统自回归 LLM 每次只生成一个 token 不同,通过 RNN 草稿模型的预测输出, 能够在每个解码步骤生成多个 ,大大减少了需要调用 LLM 验证的次数,从而提高了整体的推理速度。
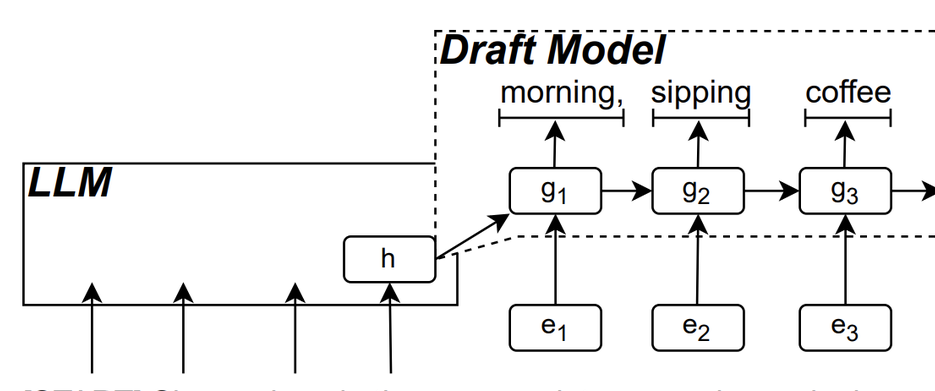
▲图源:arXiv
动态树注意力算法( Tree )则是一种优化束搜索结果的算法。
我们已经知道,在束搜索过程中会产生多个候选序列,而这些序列往往存在共享的前缀。动态树注意力算法会识别出这些共享前缀,并将它们从需要验证的 中去除,从而减少 LLM 需要处理的数据量。
某些情况下,该算法能将需要验证的 数量减少 30% 到 60%。这意味着使用动态树注意力算法后, 能够更高效地利用计算资源,进一步提高推理速度。
▲图源:
知识蒸馏是一种模型压缩技术,它能够将一个大型、复杂的模型(教师模型)的知识「蒸馏」到一个更小、更简单的模型(学生模型)中。在 中,RNN 草稿模型作为学生模型通过知识蒸馏从 LLM(教师模型)中学*。
具体来讲,蒸馏训练过程中,LLM 会给出一系列下一个可能词的「概率分布」,开发人员会基于这个概率分布数据训练 RNN 草稿模型,计算两个模型概率分布之间的差异,并通过优化算法使这个差异最小化。
在这个过程中,RNN 草稿模型不断学* LLM 的概率预测模式,从而在实际应用中能够生成与 LLM 相似的文本。
通过知识蒸馏训练,RNN 草稿模型更好地捕捉到语言的规律和模式,从而更准确地预测 LLM 的输出,并且因为其较小的规模和较低的推理计算成本,显著提高了 在有限硬件条件下的整体性能。
▲图源:阿里云开发者社区
苹果的基准测试结果显示,在 H100 GPU 上对数十亿参数的生产模型使用集成了 的 LLM 时,其贪心解码( )每秒生成的 数量提高了 2.7 倍。
在苹果自家的 M2 Ultra Metal GPU 上, 也能实现 2.3 倍的推理速度提升。苹果的研究人员表示「LLM 越来越多地用于驱动生产应用程序,提高推理效率既可以影响计算成本,也可以降低用户端延迟」。
▲图源:Apple
值得一提的是,在保持输出质量的 减少了对 GPU 资源的需求,这使得 LLM 在资源受限的环境中也能高效地运行,为 LLM 在各种硬件平台上的使用提供了新的可能性。
苹果目前已经在 上开源了这项技术,未来从中获益的公司将很可能不止英伟达一家。
- 标签:



