性能表现接近专有模型,科学家推出开源代码大模型与构建指南
研究团队的目标在于填补开源代码模型与商业化代码模型在性能与透明度上的空白,团队在论文中提供了完整的可复现数据集与训练方法。
在最初的数据预处理方面, 采用了两类主要数据源:从 的公开库中收集的原始代码以及来自 Web 数据库的代码相关的 Web 数据。
研究团队排除了所有超过 8MB 的文件,这些大多数为非文本文件。只保留特定编程语言的文件,这些语言通过文件扩展名进行识别,并参考 的 工具,最终保留了 607 种编程语言文件,以保证数据的多样性和相关性。
为了确保数据多样性并减少偏差, 采用了精确去重和模糊去重的方法,通过 哈希值对每个文档进行计算,去除完全相同的文件,利用 和局部敏感哈希(LSH)方法进一步减少内容相似的文件。在数据清洗中,还去除了无关的版权声明和个人身份信息,并通过一系列启发式规则对数据进行过滤,以确保代码的质量。
为了最大程度利用高质量的数据集, 保留了原始数据的分布特征,但对部分高资源编程语言进行了下采样,例如将 Java 数据从 409GB 下采样至 200GB,将 HTML 数据从 213GB 下采样至 64GB,以减少无信息结构化内容的影响。最终,课题组预训练阶段生成了大约 730B 的 token。
对于与代码相关的 Web 数据,团队通过 Crawl 数据集进行高质量数据的抽取,结合 模型进行自动化的数据标注与筛选,并对域名进行相关性分析和手动注释,最终获取了 330GB 的高质量的网页代码数据集。
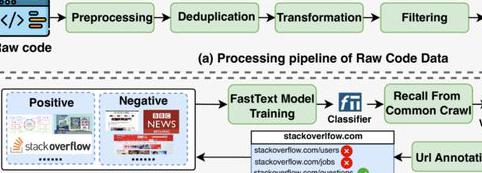
图丨 的预训练数据处理工作流程(来源:arXiv)
至于模型架构及其训练方面, 的 1.5B 参数和 8B 参数这两种规模的模型均采用标准的 架构,注意力机制使用多头注意力,以增强对复杂代码结构的建模能力。其采用了旋转位置编码(RoPE)以更好地处理长距离依赖关系,提高对上下文的理解能力。
图丨 的关键超参数概览(来源:arXiv)

,团队采用了 WSD(, , Decay)学*率调度方法,以确保模型在不同训练阶段的稳定性和高效性。训练初期通过 2000 步的 阶段逐渐增加学*率,达到峰值后在稳定阶段保持较长时间,最后在退火阶段逐渐减少学*率,以实现模型的精细调优。
消融实验的结果说明,使用高质量数据进行退火可以显著提升模型在复杂编码任务中的表现,尤其是在计算预算有限的情况下,精心选择的高质量数据能够更有效地提高模型的效率和稳定性。
训练使用了 -LM 框架,在 512 个 H100 GPU 上进行分布式训练,以确保在大规模数据上的高效计算。训练 8B 模型的总时间约为 187.5 小时,总 GPU 时数为 96000 小时。
在 的后训练阶段,团队从 Evol-、- 和 - 等多个数据库中,通过多种语言的采样收集了大量开源的指令语料。接着,再从 和 Code-290k- 等数据集中抽取真实用户查询,并使用 LLM 清洗数据,以去除低质量响应。
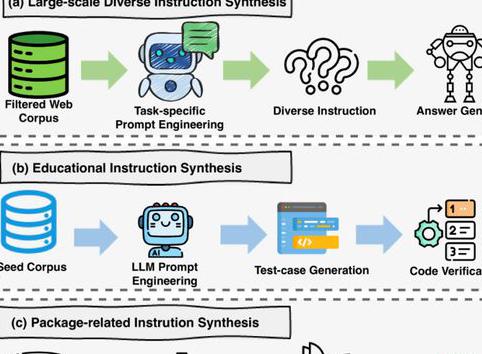
图丨 的指令数据合成工作流程(来源:arXiv)
为进一步提升模型在指令理解和代码生成任务中的表现, 还进行了双阶段的指令微调,分别针对计算机科学理论和实际编码任务进行优化。
在第一阶段,团队重点合成了与计算机科学理论相关的问题-答案 (QA) 对,使模型能够更深入地理解算法、数据结构和网络等理论概念,由此让模型能更精准地回答关于二叉搜索树、动态规划和面向对象设计等主题的问题。第二阶段,研究人员则通过从 提取的高质量代码数据集对模型进行微调,以提高其在实际的编码任务上的表现。
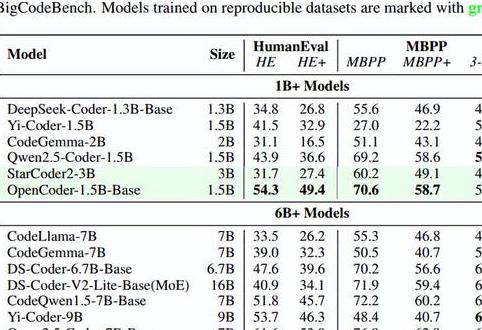
为了检验 的能力,研究人员在多个基准上将它与其他流行的开源模型(如 、Qwen2.5-Code 等)进行了比较,包括 、MBPP 和 ,覆盖了代码生成、代码补全和代码理解等不同编码场景下的任务。结果表明, 在这些任务中始终表现优于这些模型。
比如说,在 基准测试中,-8B 的 Pass@1 达到了 68.9%,超过了 -15B 的 46.3%。在 MBPP 基准测试中,-8B 的表现也达到了 79.9%,强于其他同类模型。
- 标签:



