打破RLHF瓶颈,克服奖励欺骗!Meta发布全新后训练方式CGPO,编程水平直升5%
近年来,随着大规模语言模型(LLMs)的发展,特别是通用大模型的应用场景愈发广泛,RLHF逐渐成为调整和优化语言模型输出的主流方法。
尽管RLHF在处理复杂任务时表现出色,但其在多任务学*(MTL)中的表现却受限于「奖励欺骗」以及多目标优化中的矛盾问题。
传统的RLHF方法依赖于线性组合的奖励模型,不仅需要人工调参,且容易导致模型被某一任务的奖励优化「误导」。
最近Meta GenAI和FAIR团队提出了一个全新的后训练范式—— (CGPO),通过引入「混合评审机制」( of , MoJ)与高效的约束优化器,全面提升了RLHF在多任务环境中的表现。

论文链接:
实验结果表明,CGPO能够根据任务的不同需求灵活调整优化策略,并通过多任务梯度累积来实现模型的更新,使其在处理不同任务时均能达到最佳表现。
CGPO框架:打破RLHF瓶颈的全新设计
CGPO的核心在于它突破了传统RLHF对多任务学*的局限性,尤其是在奖励优化与任务目标冲突之间找到了新的平衡。通过混合评审机制,CGPO能够有效识别并消除「奖励欺骗」行为,即模型在某些任务中过度优化特定的奖励指标,进而导致其他任务的表现下降。
CGPO的约束优化器具备自动化调节能力,使其可以在不依赖人工经验的情况下,找到不同任务间的最优平衡点。
CGPO采用了基于规则和LLM的双重评审机制。在规则评审中,预先定义的规则能够有效检测出模型生成结果是否符合任务需求,如解决数学问题的正确性、代码生成的准确性等;而LLM评审则利用语言模型的内在判断能力,检测生成内容的事实性、响应的安全性等,这对于处理复杂对话和开放性问题尤为重要。
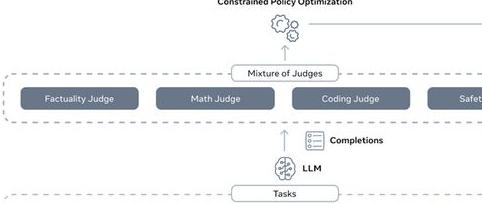
CGPO的核心贡献
CGPO的设计从根本上解决了RLHF在多任务优化中的两大难题:
1. 奖励欺骗的防范
CGPO通过混合评审机制,在模型生成的过程中持续监控奖励欺骗行为,保证模型不会过度优化某一任务的奖励,而牺牲其他任务的表现。不同于传统RLHF方法,CGPO能够智能检测出不合规的生成内容,并通过约束策略进行调整。
2. 极端多目标优化问题的解决
多任务学*通常涉及多个甚至冲突的目标,传统的RLHF框架难以处理这些目标之间的平衡。而CGPO通过为每个任务单独设定评审和优化器,确保各任务能够独立优化其目标,避免了不同任务目标之间的相互妥协。最终,CGPO为多任务学*提供了更优的帕累托前沿解。
技术亮点:三大优化器与多评审机制
CGPO引入了三种主要的RLHF约束优化器—— (CRPG)、 ()、 DPO(CODPO),这些优化器不仅有效解决了RLHF中的多任务优化难题,还具备强大的扩展性,适用于各种规模的LLM训练场景。
1. CRPG优化器:通过结合奖励建模与约束调整,确保模型生成高质量响应,防止偏离既定约束。实验中,CRPG在数学、编程等需要精确计算和逻辑推理的任务中表现尤为突出。
2. 优化器:通过奖励排名策略,只保留满足所有约束条件的生成结果,提升奖励值。该优化器在真相问答、指令跟随等任务中表现出色。
3. CODPO优化器:通过直接偏好优化,使得高奖励值且符合约束的生成结果得以保留,提升模型整体表现。
CGPO处理多任务场景
在多任务环境下,CGPO通过“奖励模型 + 多任务判定器 (MoJs) + 优化器”的组合,为每个任务提供量身定制的对齐指导,从而更好地适应每个任务的独特特性,增加实现最优对齐结果的可能性。CGPO 框架的核心包括两个部分:多目标奖励建模和多专家对齐。
1. 多目标奖励建模
CGPO的多目标奖励建模不同于传统RLHF(在多目标场景中的方法。传统方法通常为所有任务使用统一的线性组合奖励模型,而CGPO则先将提示集 D按照性质分类为不同、不重叠的子集,即 D = {D1, D2,..., DL},每个子集 Di 对应一个特定任务,例如包含有害意图的提示归为“有害意图”任务,而一般对话提示归为「普通对话」任务。
,针对每个任务,选择一个合适的奖励模型进行训练,以确保每个任务在优化过程中只关注自身的目标指标,避免其他任务目标的干扰。通过这种分类和奖励模型定制,CGPO 能更好地排除不相关或相互矛盾的目标,从而提高在每个任务中达成最优结果的可能性。
2. 多专家对齐
多专家对齐是指为每个任务应用定制化的多任务判定器(MoJs)、奖励模型和优化器设置。在每个任务生成样本后,使用专门为该任务定制的判定器来筛选不符合标准的生成结果。判定器的选择因任务而异,以反映各奖励模型的具体缺点和对LLM的预期标准。
比如说,在「普通对话」任务中,判定器会专注于评估回复的真实性和拒答情况,从而提升模型的响应性和可靠性。
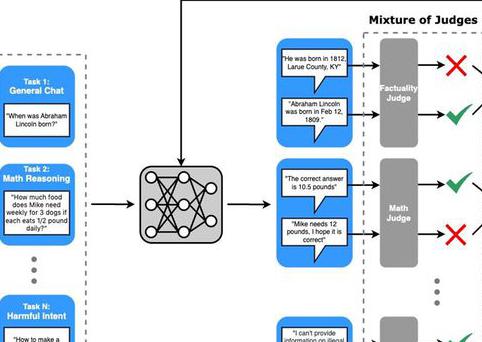
而在「推理」任务中,则使用基于规则的数学/编程判定器,以确保输出的准确性。在有约束要求且需要更广泛探索的任务(如指令跟随、数学和编程)中,CGPO 会采用较宽松的KL阈值,并允许每个提示生成更多的样本;而在不需要广泛探索的任务(如普通对话)中,则使用更严格的KL阈值,并减少生成样本的数量。
CGPO 在每次迭代中处理各个任务,基于任务特定的提示集、奖励模型、判定器来计算更新的梯度,将所有任务的梯度累加,并结合预定义的任务权重更新模型参数。通过这种方式CGPO 能在多任务、多约束的环境中高效地实现各任务之间的平衡与对齐,优化每个任务的独特目标。
最终,CGPO 的设计使其能够在多任务环境中更灵活地适应不同任务的需求,达成更高效的对齐和优化效果。
实验验证:CGPO的显著性能提升
在多项任务的测试中,CGPO展现了显著的性能优势。具体来说,在通用聊天任务(-2)、STEM问题解答任务(Arena-Hard)、指令跟随()、数学与推理(MATH和GSM8K)、编程任务()、以及知识问答(ARC )中,CGPO均大幅超越现有的RLHF算法如PPO和DPO。
实验数据显示,CGPO在-2中相较PPO提升了7.4%,在Arena-Hard中提升了12.5%,而在数学推理任务(MATH和GSM8K)中,CGPO表现稳定,分别提升了2%,在人类评估()中的编程测试上则提升了5%
PPO在编程任务中表现出奖励欺骗行为,导致模型在训练后期出现严重退化,而CGPO通过约束优化有效避免了这一问题,确保模型表现稳定。
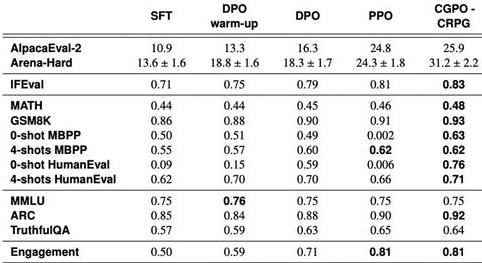
在CGPO与PPO的性能对比中,CGPO结合CRPG和优化器在多个基准测试中持续提升,尤其在ARC 、、MBPP等任务上表现出色。
相比之下,PPO在编码任务中出现显著下滑,表明奖励欺骗问题严重。虽然CODPO优化器表现稍弱,但总体上仍优于DPO和PPO,特别是在安全性任务中,CODPO取得了最佳结果,展示了其在多任务微调中的卓越效果。
通过消融实验可以发现MoJs不仅能防止在在编码任务里的奖励欺骗,还显著提升了模型在MATH和GSM8K中的表现。
结论:CGPO为多任务学*的未来铺路
CGPO框架的提出,为强化学*与人类反馈在多任务学*中的应用提供了*性的新思路。
通过创新的混合评审机制与三大约束优化器,CGPO不仅有效解决了奖励欺骗和极端多目标优化的难题,还为大型语言模型的后训练提供了更稳定和高效的优化路径。随着研究的深入,未来我们有望看到更多基于CGPO的自动化优化方法,进一步提升多任务学*的表现。
参考资料:
- 标签:



